





Inicialmente los riesgos y accidentes se aceptaron como parte del trabajo. La cantidad de lesionados no ha parado de crecer a distintas velocidades según la actividad o el sector. Los accidentes laborales producen importantes pérdidas económicas, que deben sumarse a las consideraciones éticas y legales (EU-OSHA, 2017). Reducir la siniestralidad y con ello los costes sociales y económicos de los accidentes y enfermedades profesionales es un reto continuo para los responsables políticos, investigadores y profesionales. Una de las formas de aumentar el conocimiento de cómo son causados los accidentes es mediante la técnica de investigación de accidentes. Se pretende obtener información precisa y objetiva que permita mejorar la identificación de los riesgos y controlarlos suficientemente y adecuadamente (Boraiko et al., 2008, Khanzode et al., 2012 Pillay, 2015). Para lograr esa información es necesario examinar exhaustivamente los hechos, circunstancias y causas de los accidentes buscando establecer medidas para reducir el número y gravedad de los accidentes (Harms-Ringdahl, 2004).
El sector de la construcción es actualmente considerado como una de las industrias más peligrosas (Shin et al., 2017, Tixier et al., 2017, Nini Xia et al., 2017) debido al alto número de accidentes registrados anualmente y a las graves consecuencias que esto tiene para los trabajadores, empresas y sociedad en general. Para interpretar las razones de la alta siniestralidad en la industria de la construcción, sería interesante estudiar el efecto combinado de múltiples factores (Cheng et al., 2012). Rara vez la causa de los accidentes es única y cada vez la interacción de los trabajadores con los equipos y métodos de producción que constituye una obra de construcción es más compleja (Pillay, 2014). La investigación sobre causalidad de accidentes ha demostrado que son relevantes el contexto en que se realiza una obra de construcción y sus características particulares (Gunduz et al, 2016). Los datos proporcionados por los informes de accidente de trabajo pueden utilizarse posteriormente para investigar sus causas y aprender de esas situaciones (Papadopoulos, et al. 2010).
El análisis de los datos históricos de la ocurrencia de accidentes puede proporcionar información útil para la gestión de la seguridad. Este análisis puede proporcionar lugares, causas y actividades que muestran un mayor potencial de daño, según las experiencias anteriores, y orientar hacia medidas de prevención más eficaces (Salguero-Caparros et al., 2015; Carrillo-Castrillo et al., 2017). Los resultados se pueden interpretar de la misma manera que la epidemiología (Willamson & Feyer, 1990), que proporciona las causas más frecuentes para priorizar las acciones preventivas más efectivas.
Las emergentes tecnologías de la información y tecnologías de la comunicación que tradicionalmente se utilizan para el diseño, planificación y operaciones, están siendo adoptadas actualmente para la gestión de la seguridad (Martínez-Rojas et al., 2015). Para las organizaciones tiene cada día mayor importancia la capacidad de extraer conocimiento de grandes conjuntos de datos. Técnicas como la minería de datos, que se han aplicado extensamente en diversos dominios, permiten explorar las relaciones en grandes cantidades de datos (Sanmiquel et al., 2015; Li et al., 2017; Tixier et al., 2017).
Por lo tanto, la principal contribución de este trabajo es explorar hechos que ocurren simultáneamente, expresados como reglas de asociación entre diversas variables en una gran base de datos que contiene los accidentes que se produjeron en las obras de construcción en España durante el periodo 2003-2015. Estas reglas de asociación pueden ser útiles para tratar de avanzar en la prevención de accidentes y gestión de la seguridad en la industria de la construcción.
Esta sección presenta la metodología propuesta. Para hacerlo, en primer lugar, detallamos el procesamiento previo de datos y, en segundo lugar, proporcionamos más información sobre la técnica de minería de datos seleccionada: la minería de reglas de asociación.
Antes de aplicar las técnicas de minería de datos, es necesario obtener el conjunto de datos relativos a los accidentes laborales en el sector de la construcción en Andalucía desde el período 2003-2015. El conjunto total de datos se obtiene de la base de datos digital anual sobre accidentes del Ministerio de Empleo y Seguridad Social de España (Ministerio de empleo y seguridad social, 2017). Esta base de datos contiene un total de 1.528.823 accidentes pertenecientes a todos los sectores y proporciona 58 variables para describir adecuadamente cada accidente registrado.
La información referente a los accidentes y sus circunstancias es ingresada en la base de datos mediante el sistema informático con transmisión telemática Delt@. La codificación de las variables se realiza de acuerdo a la “Metodología de Elaboración de Estadísticas de Accidentes de la Comisión Europea (ESAW)” (Eurostat, 2001).
En primer lugar hemos realizado un filtrado de los accidentes utilizando la plataforma KNIME (2018) que permite la gestión de grandes cantidades de datos.
Para extraer los accidentes relacionados con el sector de la construcción, aplicamos filtros sobre la variable <Actividad económica (V10)>, la variable <Ocupación (V5)> y la variable < Accidente o recaída (V1)>, reduciendo los datos exclusivamente a los accidentes de las actividades y ocupaciones que se detallan en la Tabla 1. Como resultado de este proceso se obtienen un total de 258.016 accidentes entre el periodo de 2003 y 2015 en Andalucía. Tras la selección de los datos, se ha utilizado el lenguaje de programación R (2018) para realizar el proceso de análisis y extracción de reglas.
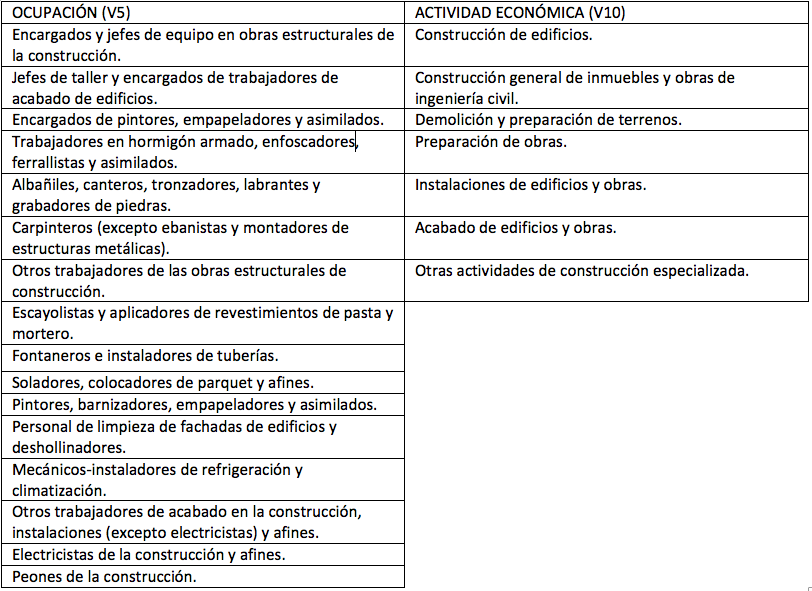
Tabla 1: Filtros aplicados a las variables Actividad económica (V10) y Ocupación (V5).
En este estudio inicial no se ha descartado ninguna de las variables descriptivas del accidente. Para cada una de éstas, hemos definido las diferentes opciones y se les ha asignado una codificación que nos permitirá analizar los resultados de manera más sencilla, un ejemplo de las más frecuentes puede observarse en la Tabla 2. Por cuestión de espacio, algunas variables sólo presentan los códigos que aparecen en la sección de resultados, como por ejemplo la V39 que presenta los distintos tipos de trabajo.
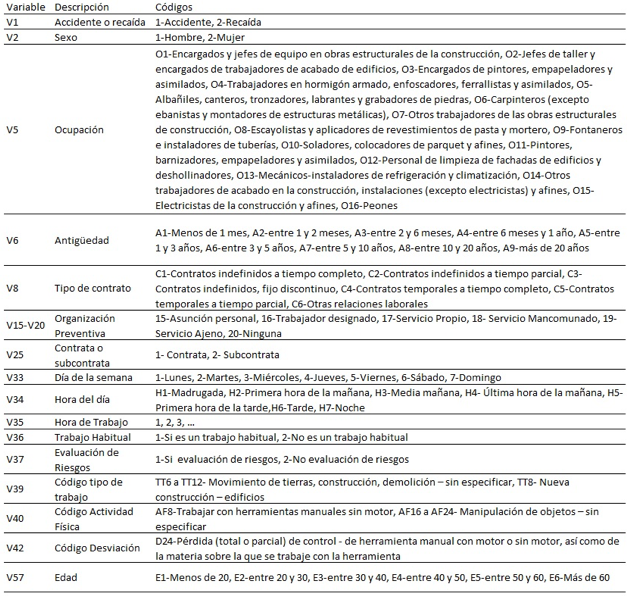
Tabla 2: Codificación de las variables más frecuentes aparecidas tras el proceso de análisis de datos.
Las reglas de asociación han sido una de las técnicas de minería de datos más utilizadas para extraer conocimiento interesante a partir de bases de datos muy extensas, ya que permite identificar y representar dependencias entre elementos (ítems) (Sanmiquel et al., 2015; Li et al., 2017). Las reglas de asociación se evalúan a través de las tres siguientes medidas: (i) Soporte de un itemset: es la frecuencia con la que el itemset ocurre en la base de datos y esta medida toma valores en el rango [0, 1]. Si el soporte es 1 indica que aparece en todas las transacciones de la base de datos, en nuestro caso en todos los accidentes registrados, y si es 0 es que no aparece en ninguna. (ii) Confianza: esta medida nos da una estimación de la probabilidad de que se produzca un hecho, en nuestro estudio un accidente. La confianza define cómo de fiable es la regla, es decir, cómo de seguro está el modelo de que cuando se da X va a ocurrir Y (XÞY). (iii) Lift: calcula el ratio entre la confianza de la regla y el consecuente de la regla. En otras palabras, mide si la regla se debió al azar. Las reglas de asociación son generalmente requeridas para satisfacer un soporte mínimo y una confianza mínima especificada por el usuario.
Como se efectúa habitualmente, hemos dividido el proceso de generación de reglas de asociación en los dos pasos siguientes:
- En primer lugar, se aplica el mínimo soporte para encontrar itemsets frecuentes en la base de datos.
- En segundo lugar, se utilizan los itemsets frecuentes y la confianza para formar las reglas.
Es fundamental conocer bien los datos que se van a analizar a la hora de aplicar técnicas de minería de datos con el fin de extraer información relevante. Para este propósito, en primer lugar, hemos analizado los items que son más frecuentes en el conjunto de datos, con un soporte mínimo de 0.2. Como se puede observar en la Figura 1, hay 8 variables que se repiten con mucha frecuencia en la base de datos de accidentes, con un soporte superior al 0.4. Estas variables son: accidente, sí es hombre, sí es un contrato temporal a tiempo completo, no es una ETT, sí es una subcontrata, sí es trabajo habitual y la organización preventiva sí es un servicio ajeno.
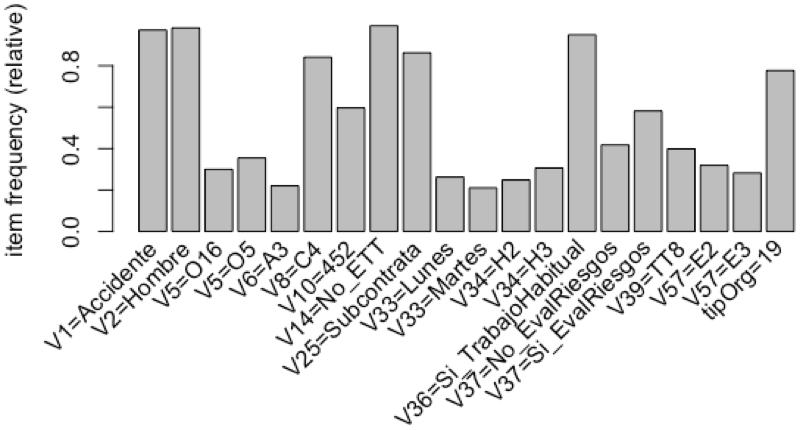
Figura 1: Frecuencia de los items
A continuación, hemos procedido a extraer los conjuntos de ítems cuyas ocurrencias superen el soporte mínimo de 0.1. Estos conjuntos se conocen como itemsets frecuentes. En este trabajo, debido a la diversidad de variables, se ha establecido un soporte bajo para incluir variables que no son tan frecuentes, pero que aportan valor al estudio. En la Figura 2 se presentan gráficamente los resultados de los itemsets frecuentes y en la Tabla 3 se presentan algunos itemsets obtenidos según el tamaño del conjunto. Además, en la tabla se presenta el soporte para cada uno de estos itemsets y el número de accidentes que lo contienen. Como era previsible tras los resultados mostrados en la Figura 1, los conjuntos frecuentes de hasta 6 elementos incluyen los ítems que presentaban un soporte más elevado. A partir de este número, aparecen otras variables de importancia, como por ejemplo el tipo de trabajo o la actividad de la empresa.
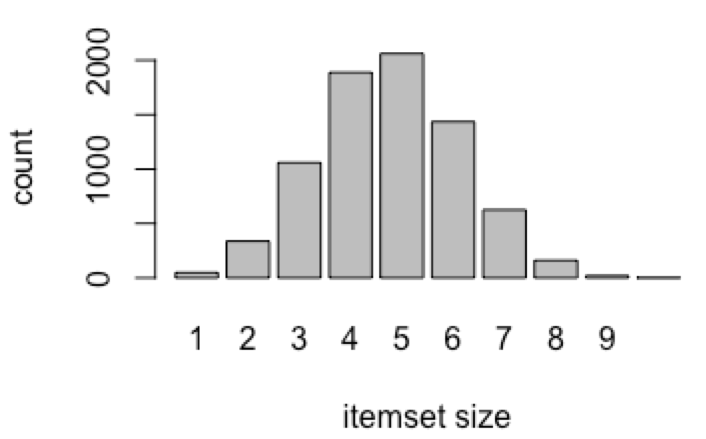
Figura 2: Itemsets frecuentes
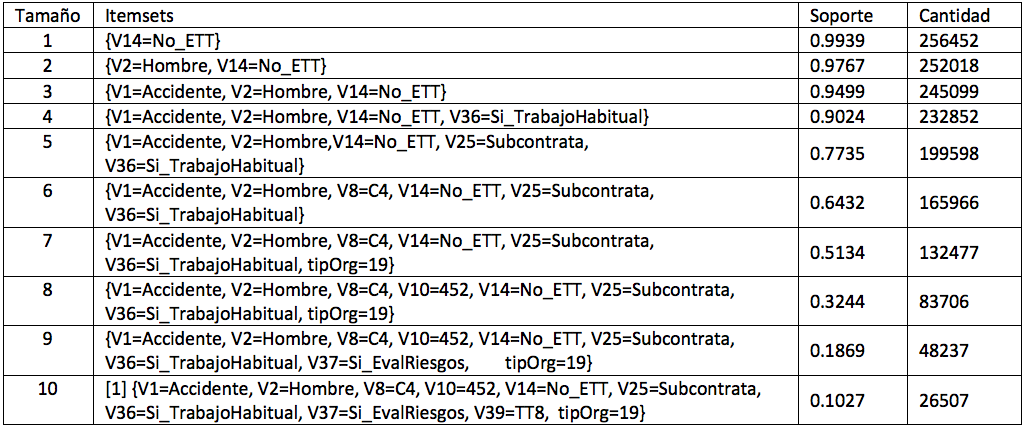
Tabla 3: Ejemplos de itemset frecuentes
Una vez que hemos obtenido los itemsets frecuentes, procedemos a calcular las reglas de asociación. Para ello, proponemos el uso del algoritmo A priori (Agrawal & Srikant, 1994) con un soporte mínimo de 0.2 y una confianza de 0.85. Con estos parámetros, se ha obtenido un conjunto de 3954 reglas. En la Figura 3 se presenta el gráfico de dispersión de las reglas obtenidas. En este trabajo nos centraremos en las reglas que aparecen en color rojo más oscuro, ya que presentan un buen valor para lift y confianza y el soporte es representativo.
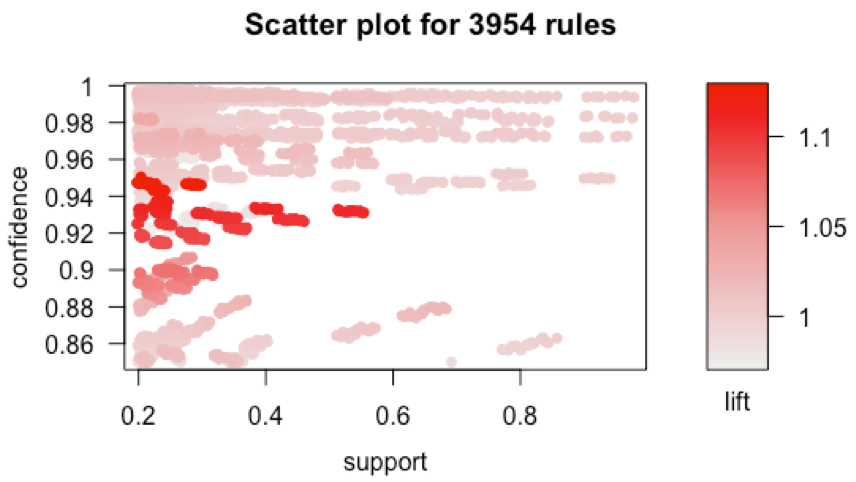
Figura 3: Gráfico de dispersión en función de las medidas de soporte y confianza
Si continuamos explorando las reglas obtenidas, en la Figura 4 podemos distinguir, de manera gráfica, el tamaño de las reglas en relación al número de ítems que la compone. Podemos observar que las reglas que presentan un muy alto valor tanto para las medidas de confianza y soporte, se componen de 2 o 3 ítems. En cuanto el número de ítems va aumentando en número de elementos, el soporte se reduce, pero no la confianza. Según los resultados de las gráficas 3 y 4, las reglas que analizaremos son aquellas que se componen de entre 5 y 8 elementos con un soporte entre 0.2 y 0.4 y una confianza por encima del 0.9.
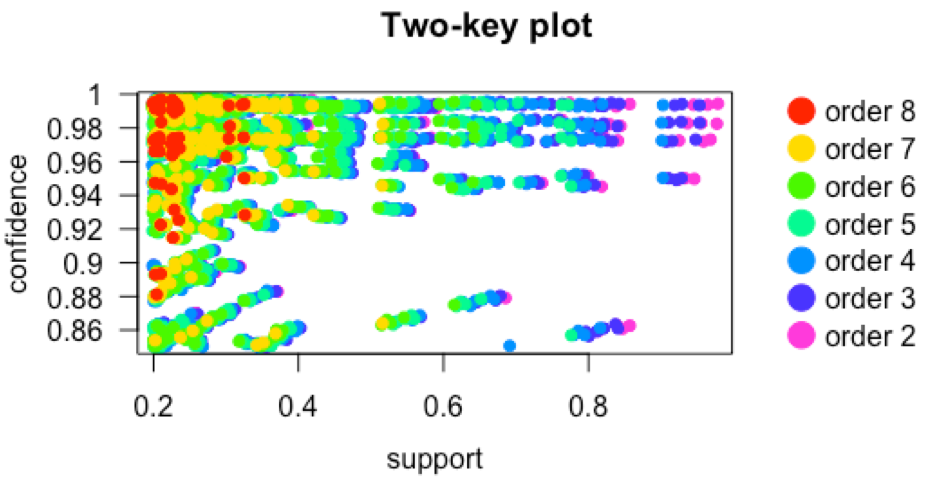
Figura 4: Dimensión de las reglas en base de los ítems
Del total de reglas obtenidas en este rango, vamos a filtrar sólo aquellas en las que aparece como hecho el accidente de modo que se pueden analizar las variables más comunes que conducen a éste. En la tabla 4 se presentan algunas de estas reglas, así como las medidas de soporte y confianza para cada una de ellas. Como se puede observar en las reglas obtenidas, además de los items frecuentes detallados con anterioridad, se observa que aparecen otras variables tales como la hora del día, la actividad física o la desviación que es el hecho anormal que se aparta del proceso habitual y que desencadenó el accidente.
Las reglas se proclaman como declaraciones expresadas en lenguaje sencillo. Por ejemplo, la primera regla de la Tabla 4 puede enunciarse como: “En el sector de la construcción, dado un hombre, con contrato a tiempo completo que no trabaja en una ETT, que trabaja en una subcontrata, que realiza un trabajo habitual en la tercera hora de su jornada un lunes; tiene la probabilidad de tener un accidente del 98%”. Estas primeras reglas son muy generales ya que se han incluido variables que presentan una frecuencia muy elevada. En posteriores análisis, se deberían eliminar ciertas variables con el fin de obtener resultados más específicos.

Tabla 4: Reglas de asociación obtenidas cuyo consecuente es el accidente
En este trabajo, se ha propuesto un enfoque preliminar para explorar relaciones desconocidas entre items de la base de datos oficial de accidentes laborales de Andalucía entre el año 2003 y 2015 para el sector de la construcción. Para ello, hemos seguido los pasos del proceso de generación de reglas de asociación. El primer paso nos ha permitido conocer con más detalle la base de datos, explorando los items frecuentes y su soporte respecto al total de accidentes. En el segundo paso, el proceso de extracción automática de reglas, hemos presentado gráficas que permiten interpretar fácilmente los datos. Por último, hemos presentado algunas de las reglas más generales como resultado.
Como trabajo futuro proponemos reducir el número de variables de entrada, eliminando aquellas que son muy frecuentes, y analizar los casos que presentan un soporte menor pero que son representativos en el conjunto de los datos.
Este trabajo ha sido parcialmente financiando por el Ministerio de Economía y Competitividad del Gobierno de España por el proyecto de financiación BIA2016-79270-P y el programa posdoctoral (FJCI- 2015-24093), así́ como por el Ministerio de Educación, Cultura y Deportes del Gobierno de España por su apoyo a través del programa predoctoral (FPU 2016/03298).
Agrawal, R., & Srikant, R. (1994, September). Fast algorithms for mining association rules. In Proc. 20th int. conf. very large data bases, VLDB (Vol. 1215, pp. 487-499).
Boraiko, C., Beardsley, T., & Wright, E. (2008). Accident Investigations One Element of an Effective Safety Culture. Professional Safety, 53(09).
Carrillo-Castrillo, J. A., Trillo-Cabello, A. F., & Rubio-Romero, J. C. (2017). Construction accidents: identification of the main associations between causes, mechanisms and stages of the construction process. International journal of occupational safety and ergonomics, 23(2), 240-250.
Cheng, C. W., Leu, S. S., Cheng, Y. M., Wu, T. C., and Lin, C. C. (2012). “Applying data mining techniques to explore factors contributing to occupational injuries in Taiwan's construction industry.” Accident Analysis and Prevention, Vol. 48, pp. 214-222, DOI: 10.1016/ j.aap.2011.04.014.
EU-OSHA (2017). An international comparison of the cost of work-related accidents and illnesses. Publications Office of the European Union, Luxembourg. Available at: https://osha.europa.eu/en/tools-and-publications/publications/international-comparison-cost-work-related-accidents-and/view
Eurostat, 2001. European Statistics on Accidents at Work (ESAW) – Methodology. 2001. Luxemburgo: DG Employment and Social Affairs. European Commission.
Gunduz, M., Birgonul, M. T., & Ozdemir, M. (2016). Fuzzy structural equation model to assess construction site safety performance. Journal of Construction Engineering and Management, 143(4), 04016112.
Harms-Ringdahl, L. (2004). Relationships between accident investigations, risk analysis, and safety management. Journal of Hazardous materials, 111(1-3), 13-19.
Khanzode VV, Maiti J, Ray P. Occupational injury and accident research: A comprehensive review. Safety Science. 2012; 50 (5): 1355-1367.
Li, H., Li, X., Luo, X., & Siebert, J. (2017). Investigation of the causality patterns of non-helmet use behavior of construction workers. Automation in Construction, 80, 95-103.
Martínez-Rojas, M., Marín, N., & Vila, M. A. (2015). The role of information technologies to address data handling in construction project management. Journal of Computing in Civil Engineering, 30(4), 04015064.
Nini Xia, Xueqing Wanga, Mark A. Griffin, Chunlin Wu, Bingsheng Liu (2017). Do we see how they perceive risk? An integrated analysis of risk perception and its effect on workplace safety behavior. Accident Analysis and Prevention, 106, 234-242.
Papadopoulos, G., Georgiadou, P., Papazoglou, C., & Michaliou, K. (2010). Occupational and public health and safety in a changing work environment: An integrated approach for risk assessment and prevention. Safety Science, 48(8), 943-949.
Pillay, M. (2014). Progressing zero harm: a review of theory and applications for advancing health and safety management in construction. Achieving Sustainable Construction Health and Safety.
Pillay, M. (2015). Accident causation, prevention and safety management: a review of the state-of-the-art. Procedia Manufacturing, 3, 1838-1845.
R, (2018). https://www.r-project.org/
Salguero-Caparros, F., Suarez-Cebador, M., & Rubio-Romero, J. C. (2015). Analysis of investigation reports on occupational accidents. Safety science, 72, 329-336.
Sanmiquel, L., Rossell, J. M., & Vintró, C. (2015). Study of Spanish mining accidents using data mining techniques. Safety science, 75, 49-55.
Shin, D. P., Park, Y. J., Seo, J., & Lee, D. E. (2017). Association rules mined from construction accident data. KSCE Journal of Civil Engineering, 1-13.
Tixier, A. J. P., Hallowell, M. R., Rajagopalan, B., & Bowman, D. (2017). Construction safety clash detection: identifying safety incompatibilities among fundamental attributes using data mining. Automation in Construction, 74, 39-54.
Willamson, A., & Feyer, A. M. (1990). Behavioural epidemiology as a tool for accident research. Journal of Occupational Accidents, 12(1-3), 207-222.
Papers relacionados











