
Los datos no descansan
Los datos no descansan

En la inmensidad de la red navegas diariamente entre grandes volúmenes de datos que no servirían de mucho si no se almacenaran, se clasificaran y se analizaran. A partir de estos macrodatos se genera conocimiento, productos y servicios. La inteligencia de datos o el fenómeno big data como hoy lo conocemos está revolucionando la ciencia, la economía, la política e incluso nuestro estilo de vida.
¿Qué son los datos?
Podemos obtener datos de cualquier cosa que nos rodea, ya sean objetos, personas o lugares. Piensa por ejemplo en un objeto: puedes describir su tamaño, su color, el material o materiales de los que está hecho y el lugar donde se encuentra. De una persona, podemos decir su nombre, edad, fecha de nacimiento, sexo y un sinfín de datos más.
Pero no todos los datos son estáticos. El lugar donde naciste no puede cambiar, pero sí el lugar donde te encuentras en cada momento.
Tu actividad también genera datos. Por ejemplo, los viajes en transporte público registran datos a través de los abonos de transporte, las compras a través de las tarjetas de crédito, los GPS nos geolocalizan y nuestro consumo de energía o nuestra actividad en las redes sociales quedan registradas.
Los datos nos pueden ayudar a entender las cosas. Por ejemplo, fijémonos en la fotografía de fondo en la que aparecen unos lápices de colores.
Podemos obtener muchos más datos de los que parecen a simple vista. Podemos decir, por ejemplo, que son lápices, de qué colores son, cuántos hay, que sirven para colorear, cuáles están más gastados, etc. Cada uno de estos datos responde a diferentes preguntas.
Existen distintas tipologías de datos pero vamos a fijarnos en dos grandes categorías: los datos cuantitativos y los datos cualitativos.
DATOS CUANTITATIVOS
Son los datos que se pueden expresar en números, como medidas, cantidades o calificaciones. La demografía de un país o una ciudad se expresa en datos cuantitativos: número de habitantes, superficie, densidad de la población, número de mujeres y hombres, edad media de sus habitantes, etc.
El deporte está lleno de datos cuantitativos: goles, canastas, puntos, clasificaciones, tiempo, velocidad, potencia…
Pongamos otro ejemplo: cuando una persona está en el hospital, los sanitarios que la atienden recogen a diario los datos de su estado y de cómo evoluciona. Por ejemplo, le toman la temperatura, anotan la dosis de medicamentos que se le suministran y la hora. Estos son datos cuantitativos.
DATOS CUALITATIVOS
Estos datos describen las características de algo como, por ejemplo, de qué color es o qué forma tiene. Incluso pueden referirse a emociones o sensaciones. Los datos cualitativos se expresan en palabras y textos, por lo que son más difíciles de medir y comparar que los cuantitativos. Las fotografías, las grabaciones o las respuestas de una entrevista pueden ser datos cualitativos.
La investigación científica y las ciencias sociales suelen combinar estos dos tipos de datos para explicar hechos y situaciones. Es importante que entendamos que un dato por sí mismo no nos aporta una información de gran valor. Tenemos que procesarlo (validándolo, clasificándolo, analizándolo…) para poder ponerlo en contexto y que nos aporte un conocimiento valioso, convirtiéndose así en un dato útil. Pero también la utilidad de los datos dependerá del análisis que quieras realizar y de la información que estés buscando.
Aun así, no todos los datos obtenidos tienen por qué proporcionarnos información valiosa. Internet está plagado de datos, por ello es necesario detectar qué datos pueden ser útiles y cuáles no.
Los metadatos
El término “meta” viene de una palabra griega que significa, entre otras cosas, “junto a” o “asociado a”. Por tanto, podríamos definir los metadatos como datos sobre otros datos.
Este sistema de registro de información que ahora nos parece propio del mundo digital es un método que tradicionalmente se ha usado en las bibliotecas para listar y clasificar los libros y documentos y facilitar su búsqueda. De esta manera se registra el título, el autor, el año de publicación, la materia y la signatura topográfica que señala el lugar donde está colocado el libro.
Aparte de en las bibliotecas, ¿dónde más podemos encontrar metadatos? Pues en tu bolsillo, por ejemplo. Cada vez que haces una foto o grabas un vídeo con tu smartphone se almacena también la fecha y la hora de su captura. Ahí los tienes: estos datos son metadatos y pueden revelar incluso con qué cámara se tomó la foto, el tiempo que estuvo abierto el obturador y el punto exacto donde la hiciste, localizado vía GPS.
Cuando subimos nuestras fotos a internet, estamos subiendo también toda la información que estas contienen. Y lo mismo pasa con nuestros comentarios de Facebook, por ejemplo. La fecha, la hora y el sitio de la publicación que acompañan al comentario también son metadatos. Las páginas web están llenas de metadatos, aunque a menudo no son visibles.
Con el aumento de datos en la red surgió la necesidad de clasificación de todos estos datos y de la información que llevan relacionada: hay diferentes clasificaciones de metadatos relacionados con características referentes a la funcionalidad, la estructura o quién los produce. Algunos ejemplos de clasificación son:
SEGÚN DOMINIO:
- Metadatos para describir recursos de información en la Web:
Ejemplo: Dublin Core (DCMI) - Metadatos para la descripción de archivos:
Ejemplo: el Encoded Archival Description (EAD) - Metadatos para la descripción museística:
Ejemplo: Consortium for the Interchange Museum Information (CIMI) - Metadatos para definir registros de catálogos en bibliotecas y centros de documentación:
Ejemplo: MARC para la descripción de recursos electrónicos - Metadatos para recursos geográficos y espaciales:
Ejemplo: Content Standard for Digital Geospatial Metadata (CSDGM) o el Directory Interchange Format (DIF) de la NASA. - Metadatos para describir recursos de información gubernativa y administrativa:
Ejempo: Goverment Information Locator Service (GILS)
SEGÚN FUNCIÓN:
- Metadatos administrativos:
Para gestionar y administrar recursos digitales (localización, institución o autor que genera, guarda y mantiene los recursos, fecha de creación y actualización, seguimiento y control de versiones, etc.) - Metadatos descriptivos:
Describen e identifican recursos de información. Permiten a los usuarios la búsqueda y recuperación. - Metadatos estructurales:
Facilitan la navegación y la presentación de los recursos. Proporcionan información sobre la estructura interna de los documentos, así como la relación entre ellos.
Material de referencia como imagen ejemplificativa para mostrar metadatos:

Otro ejemplo es el de una canción en formato MP3. Podríamos explicarlo así: el “dato” es el sonido y los metadatos el título de la obra, álbum, año, autor, carátula, género, etc.
Big Data: cuando los datos se vuelven inteligentes
Los datos y metadatos que se encuentran en la red no servirían de mucho si no se almacenaran, se clasificaran y se analizaran. La disciplina que se encarga de este proceso recibe el nombre de inteligencia de datos o Big Data.
A partir de estos macrodatos podemos generar conocimiento, productos y servicios. Por ejemplo, nos permiten predecir el tiempo, analizar parámetros de salud, mejorar la eficiencia energética o vender más y mejor. Por eso la inteligencia de datos está revolucionando la ciencia, la economía, la política y nuestro estilo de vida.
Se utiliza la inteligencia de datos cuando:
- Introducimos mal una palabra de una búsqueda y Google nos la corrige.
- Amazon nos muestra productos que podrían interesarnos según lo que hayamos comprado antes.
- Snapchat nos descubre usuarios y noticias.
- Facebook nos sugiere amistades con gente que es probable que conozcamos.
- Spotify elabora una lista semanal de canciones según nuestros gustos.
Las cuatro uves del Big Data
Estas primeras cuatro uves (ya veremos más adelante alguna más) sirven para recordar y describir las características principales del Big Data: la gestión de un gran volumen de datos, a la mayor velocidad posible, almacenados junto a una extensa variedad de información, que debe estar verificada.
VOLUMEN
El crecimiento de los datos en la red es constante. Por eso se dice que "los datos nunca duermen". Ya sea de día o de noche, las 24 horas y en cualquier parte del mundo, se generan datos. Esta producción ininterrumpida se dobla cada 40 meses, lo que quiere decir que se generan más datos en un día de los que han existido en los últimos 20 años.
VELOCIDAD
Imprescindible en la creación y análisis de los datos. Dado que estamos generando datos constantemente, necesitamos rapidez para disponer de esa información en tiempo real. La información se procesa tan rápido que podemos conocer datos del presente inmediato, y consultar qué está ocurriendo en el mundo ahora mismo. Esto nos permite hacer análisis bastante detallados y complejos que a menudo se integran en otros procesos de trabajo y sistemas.
VARIEDAD
Hay datos de muchos formatos y tipologías, según su procedencia. Podemos clasificar los macrodatos en:
- Datos públicos: datos que tienen las administraciones públicas (por ejemplo, datos sobre transporte, uso de energía, sanidad, etc.).
- Datos privados: datos derivados de transacciones comerciales, de la navegación web, del uso de la telefonía móvil, etc.
- Datos comunitarios: datos producidos principalmente en las redes sociales, contenidos generados por el usuario, etc.
- Datos quantified self: datos obtenidos y proporcionados por las propias personas que miden y cuantifican sus comportamientos y acciones. Por ejemplo, los datos monitorizados sobre las pulsaciones durante la realización de ejercicio físico que son recogidos por dispositivos móviles.
VERACIDAD
Los datos obtenidos deben ser fiables, íntegros y auténticos, por lo que es necesario confirmar su veracidad. Y ¿cómo sabemos si los datos son válidos? Esto dependerá de las fuentes y los recursos que hayamos empleado para obtenerlos.
Los datos contra el virus H1N1
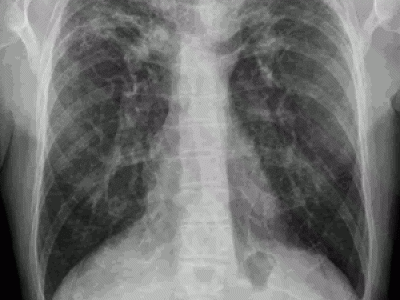
En la publicación La revolución de los datos masivos (2013), Viktor Mayer-Schöberger y Kenneth Cukier nos explican que en 2009 se descubrió un nuevo virus de la gripe que recibió el nombre de H1N1. En pocas semanas, se propagó tanto que las autoridades sanitarias de todo el mundo temieron que se produjera una pandemia global.
Dado que no existía ninguna vacuna, las autoridades decidieron que la mejor manera de combatir el virus era ralentizar todo lo posible su propagación. Para ello, primero debían localizar dónde se estaba manifestando con más fuerza.
En Estados Unidos, los Centros de Control y Prevención de Enfermedades pidieron a los médicos que avisaran de nuevos casos de gripe, pero esta se propagaba a mayor velocidad de la que se detectaba. Esto se debe a que gran parte de los pacientes tardaban días en acudir a los centros y los médicos a veces tardaban días en enviar los informes.
La transmisión de la información era lenta, por lo que la enfermedad no dejaba de propagarse.
Casualmente, unas semanas antes de que el virus alertara a las autoridades sanitarias, un grupo de ingenieros de Google publicó un estudio gracias al cual habían podido predecir la propagación de la gripe invernal (gripe común) en Estados Unidos, por regiones, analizando las palabras que buscaba la gente en internet.
Dado que Google recibe más de tres mil millones de búsquedas diarias y todas son archivadas, hay una ingente cantidad de información disponible para analizar y comparar.
Google tomó los cincuenta millones de términos más comunes que buscan los ciudadanos norteamericanos y los comparó con los datos de los Centros de Control y Prevención de Enfermedades sobre la gripe estacional entre 2003 y 2008. La intención era identificar a los enfermos de gripe por las búsquedas que hacían en internet como “remedios para la tos y la fiebre”.
De esta manera, cruzando los datos de las búsquedas y los datos de los enfermos de gripe entre 2007 y 2008, pudieron dar con modelos matemáticos que les permitieran predecir la propagación de la gripe casi en tiempo real basándose en las búsquedas que se estaban realizando en internet.
Este método no es perfecto y en la actualidad no se utiliza, pero en aquella ocasión sirvió para que las autoridades sanitarias supieran más sobre el virus sin necesidad de que los enfermos llegaran a las consultas, tan solo aprovechando el asombroso método de Google sobre los datos masivos.